
サントリーウエルネス DX推進部 エンジニアリングGの武田です。
フルスタックエンジニアとしてコンタクトセンターで使うシステムが抱える課題に日々取り組んでいます。
弊社ではお客様とお話した内容を対話要約として保存しています。
お客様の声を詳しく分析するための方法の一つとして、対話要約を全文検索出来るようにすることを検討しています。
この記事では「テキストデータをElasticsearchに投入して全文検索出来るようにする方法」を紹介したいと思います。
この記事から分かること
テキストデータをElasticseachに投入してKibanaで可視化する方法
キーワード
全文検索というと転置インデックス、N-Gram、シノニム、ユーザー辞書、文字列正規化、頻出語句除去など様々な技術要素がありますが今回は触れません。
| キーワード | 概要 |
|---|---|
| Elasticsearch | 全文検索エンジンです。大量の文書に対して高速で全文検索することが出来るようになります。 |
| Kibana | Elasticserach用のデータ可視化ツールです。 |
| Docker | コンテナ型の仮想環境プラットフォームです。設定ファイルから同一のアプリケーション実行環境を立ち上げることが出来るようになります。 |
| 形態素解析 | 文章を意味を持つ最小の単位に分割・判別することです。例:「セサミンには抗酸化作用があります」->「セサミン(名刺)」「に(格助詞)」「は(係助詞)」「抗(接続詞)」「酸化(名刺)」「作用(名刺)」「が(格助詞)」「あり(動詞)」「ます(助動詞)」 |
| タグクラウド | 件数、出現頻度、重要度を加味してタグの一覧を可視化したものです。 |
| 全文検索 | 複数の文書の先頭から末尾までテキスト全てを対象に特定の文字列を検索することです。 |
構成
将来的には以下のようにデータをElasticsearchに連携し、全文検索出来る環境を作っていきたいと考えています。
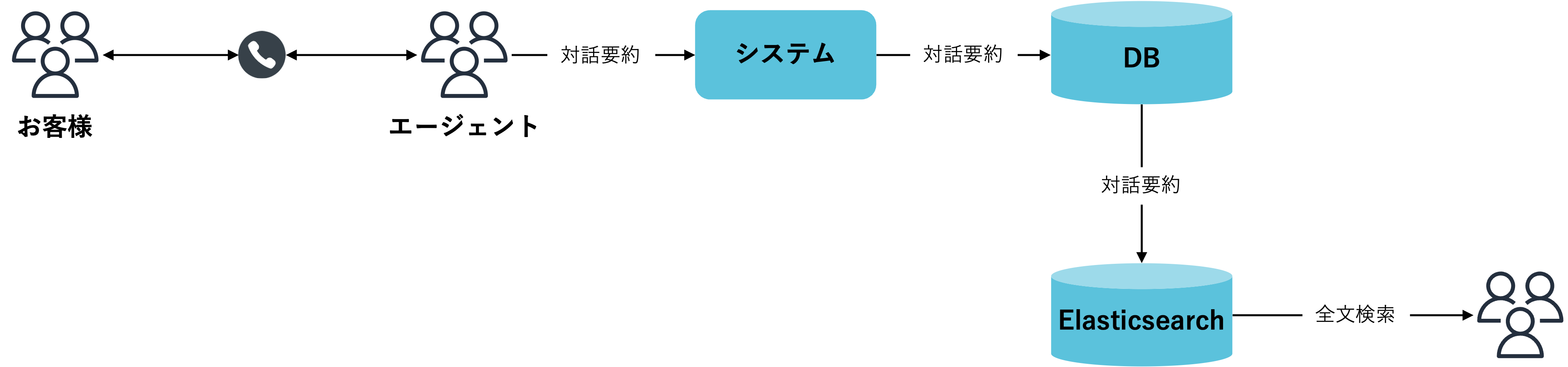
※弊社ではコールセンターにて従事していただいているオペレーターをエージェントと言います。
前段階として今回はDockerでElastic Stack(Elasticsearch、Kibana、Logstash、Beats)を構築しました。
CSVを所定のディレクトリに置くとBeatsがファイルを検知してデータをLogstashに送り、Logstashでデータを処理してElasticsearchに投入し、KibanaでElasticsearchのデータを可視化します。
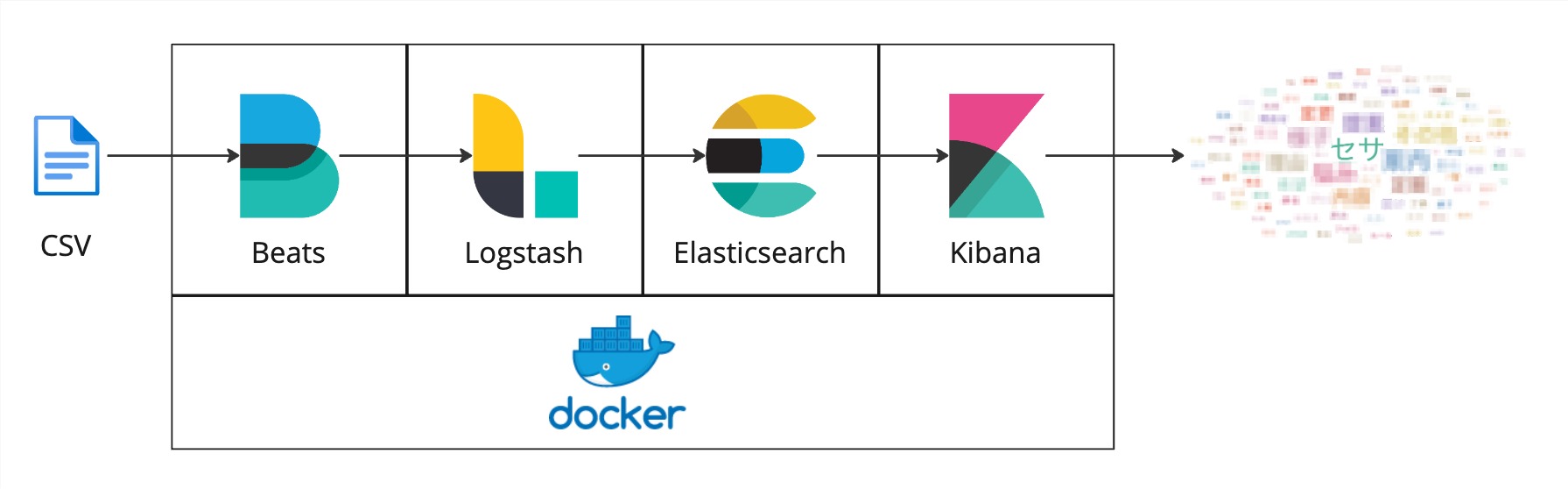
| MW | 概要 |
|---|---|
| Beats | データシッパーです。今回はCSVをLogstashに転送します。 |
| Logstash | データ処理パイプラインです。今回はFilebeatから受信したデータをElasticsearchに流します。 |
| Elasticsearch | 全文検索エンジンです。テキストを形態素解析し全文検索出来るようにします。 |
| Kibana | Elasticserach用のデータ可視化ツールです。Elasticsearchに投入したデータをフリーワード検索したり、タグクラウドを作成したりすることが出来ます。 |
テキストデータ準備
今回は対話要約のテキストデータ(CSV形式)を使います。
ヘッダーは "日時", "対話内容", "ID" です。
$ head -n 3 conversation_history.csv
"2023/08/01 09:00","お話内容その1","00001"
"2023/08/01 10:00","お話内容その2","00002"
"2023/08/01 11:00","お話内容その3","00003"
Elastic Stack 構築
Elasticsearch、Kibana、Logstash、BeatsをDockerで構築します。
コンテナ作成起動
$ docker-compose up
構成
$ tree . -L 3
.
├── docker-compose.yml
├── elasticsearch
│ ├── Dockerfile
│ ├── config
│ │ └── stopwords.txt
│ ├── data
│ └── mappings.json
├── filebeat
│ ├── conf
│ │ └── filebeat.yml
│ └── log
│ └── conversation_history_20230803.csv
└── logstash
└── pipeline
└── logstash.conf
docker-compose.yml
Elasticsearchにプラグインを入れたいため別にDockerfileを用意しました。
データ投入を高速で処理するためにElasticsearch、Logstashのメモリを固定で設定していますが、こちらはマシンスペックに応じて適宜変更してください。
version: "3"
services:
elasticsearch:
build: elasticsearch
environment:
- discovery.type=single-node
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms2048m -Xmx2048m"
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 9200:9200
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
- ./elasticsearch/config/stopwords.txt:/usr/share/elasticsearch/config/stopwords.txt
kibana:
image: docker.elastic.co/kibana/kibana:7.17.0
ports:
- 5601:5601
logstash:
image: docker.elastic.co/logstash/logstash:7.17.0
ports:
- 5044:5044
environment:
- "LS_JAVA_OPTS=-Xms2048m -Xmx2048m"
volumes:
- ./logstash/pipeline:/usr/share/logstash/pipeline
filebeat:
image: docker.elastic.co/beats/filebeat:7.17.0
volumes:
- ./filebeat/conf/filebeat.yml:/usr/share/filebeat/filebeat.yml
- ./filebeat/log:/usr/share/filebeat/log
- /var/run/docker.sock:/var/run/docker.sock
user: root
elasticsearch/Dockerfile
形態素解析のプラグインを入れます。
FROM docker.elastic.co/elasticsearch/elasticsearch:7.17.0
RUN elasticsearch-plugin install analysis-kuromoji
RUN elasticsearch-plugin install analysis-icu
elasticsearch/stopwords.txt
除去する頻出語句を定義します。 stopwords.txtの詳細を知りたい方はLuceneのstopwords.txtを参考にしてください。
filebeat/conf/filebeat.yml
filebeat/log配下のCSVをLogstashに流すように設定しています。
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/share/filebeat/log/*conversation_history*.csv
output.logstash:
hosts: ["logstash:5044"]
logstash/pipeline/logstash.conf
FilebeatのCSVを受けてElasticserachに流す設定をしています。
logstash.conf
input {
# input from Filebeat
beats {
port => 5044
}
}
filter {
csv {
columns => ["date", "conversation", "id"]
}
date {
match => ["Date", "YYYY-MM-dd HH:mm"]
timezone => "UTC"
}
}
output {
elasticsearch {
hosts => [ 'elasticsearch' ]
index => "conversation_history"
}
}
Elasticserachデータ投入
スキーマ定義(elasticsearch/mapping.json)
対話内容に形態素解析、N-Gramをかけます。
mapping.json
{
"settings": {
"analysis": {
"char_filter": {
"normalize": {
"type": "icu_normalizer",
"name": "nfkc",
"mode": "compose"
}
},
"tokenizer": {
"ja_kuromoji_normal_tokenizer": {
"mode": "normal",
"type": "kuromoji_tokenizer",
"discard_compound_token": true
},
"ja_kuromoji_search_tokenizer": {
"mode": "search",
"type": "kuromoji_tokenizer",
"discard_compound_token": true
},
"ja_ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 3,
"token_chars": [
"letter",
"digit"
]
}
},
"filter": {
"ja_index_synonym": {
"type": "synonym",
"lenient": false,
"synonyms": []
},
"ja_search_synonym": {
"type": "synonym_graph",
"lenient": false,
"synonyms": []
},
"ja_custom_stop": {
"type": "stop",
"stopwords_path": "stopwords.txt"
},
"kuromoji_custom_part_of_speech": {
"type": "kuromoji_part_of_speech",
"stoptags": [
"接続詞",
"助詞",
"助詞-格助詞",
"助詞-格助詞-一般",
"助詞-格助詞-引用",
"助詞-格助詞-連語",
"助詞-接続助詞",
"助詞-係助詞",
"助詞-間投助詞",
"助詞-並立助詞",
"助詞-終助詞",
"助詞-副助詞/並立助詞/終助詞",
"助詞-連体化",
"助詞-副詞化",
"助詞-特殊",
"助動詞",
"記号",
"記号-一般",
"記号-読点",
"記号-句点",
"記号-空白",
"記号-括弧開",
"記号-括弧閉",
"その他-間投",
"フィラー",
"非言語音"
]
}
},
"analyzer": {
"ja_kuromoji_index_analyzer": {
"type": "custom",
"char_filter": [
"normalize"
],
"tokenizer": "ja_kuromoji_normal_tokenizer",
"filter": [
"kuromoji_baseform",
"kuromoji_custom_part_of_speech",
"ja_index_synonym",
"cjk_width",
"ja_custom_stop",
"kuromoji_stemmer",
"lowercase"
]
},
"ja_kuromoji_search_analyzer": {
"type": "custom",
"char_filter": [
"normalize"
],
"tokenizer": "ja_kuromoji_normal_tokenizer",
"filter": [
"kuromoji_baseform",
"kuromoji_custom_part_of_speech",
"ja_search_synonym",
"cjk_width",
"ja_custom_stop",
"kuromoji_stemmer",
"lowercase"
]
},
"ja_ngram_index_analyzer": {
"type": "custom",
"char_filter": [
"normalize"
],
"tokenizer": "ja_ngram_tokenizer",
"filter": [
"cjk_width",
"kuromoji_stemmer",
"lowercase"
]
},
"ja_ngram_search_analyzer": {
"type": "custom",
"char_filter": [
"normalize"
],
"tokenizer": "ja_ngram_tokenizer",
"filter": [
"cjk_width",
"kuromoji_stemmer",
"lowercase"
]
}
}
}
},
"mappings": {
"properties": {
"date": {
"type": "date",
"format": "yyyy/MM/dd HH:mm"
},
"conversation": {
"type": "text",
"fielddata": true,
"search_analyzer": "ja_kuromoji_search_analyzer",
"analyzer": "ja_kuromoji_index_analyzer",
"fields": {
"ngram": {
"type": "text",
"search_analyzer": "ja_ngram_search_analyzer",
"analyzer": "ja_ngram_index_analyzer"
}
}
},
"id": {
"type": "keyword"
}
}
}
}
スキーマ作成
conversation_historyというインデックス名でスキーマを作成します。
$ cd elasticsearch
$ curl -XPUT "http://localhost:9200/conversation_history?pretty" -H "Content-Type: application/json" -d @mappings.json
データ投入
filebeat/logにCSVを置くとBeatsがファイルを検知しLogstashに流しElasticsearchにデータが投入されます。
(Elasticsearchにデータを投入することをインデキシングといいます。)
データが入っていることを確認します。
$ curl -sS -XGET "http://localhost:9200/conversation_history/_count?pretty"
{
"count" : 1000,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
Kibana設定
http://localhost:5601 にアクセスするとKibanaのホーム画面が表示されます。
Elasticsearchインデックス確認
Managemant/Stack Management > Data/Index Managementより確認できます。
Kibanaインデックスパターン作成
Managemant/Stack Management > Kibana Index Patterns > Create index patternの順に進み下記設定で [Create index pattern] をクリックします。
| key | value |
|---|---|
| Name | conversation_history* |
| Timestamp field | date |
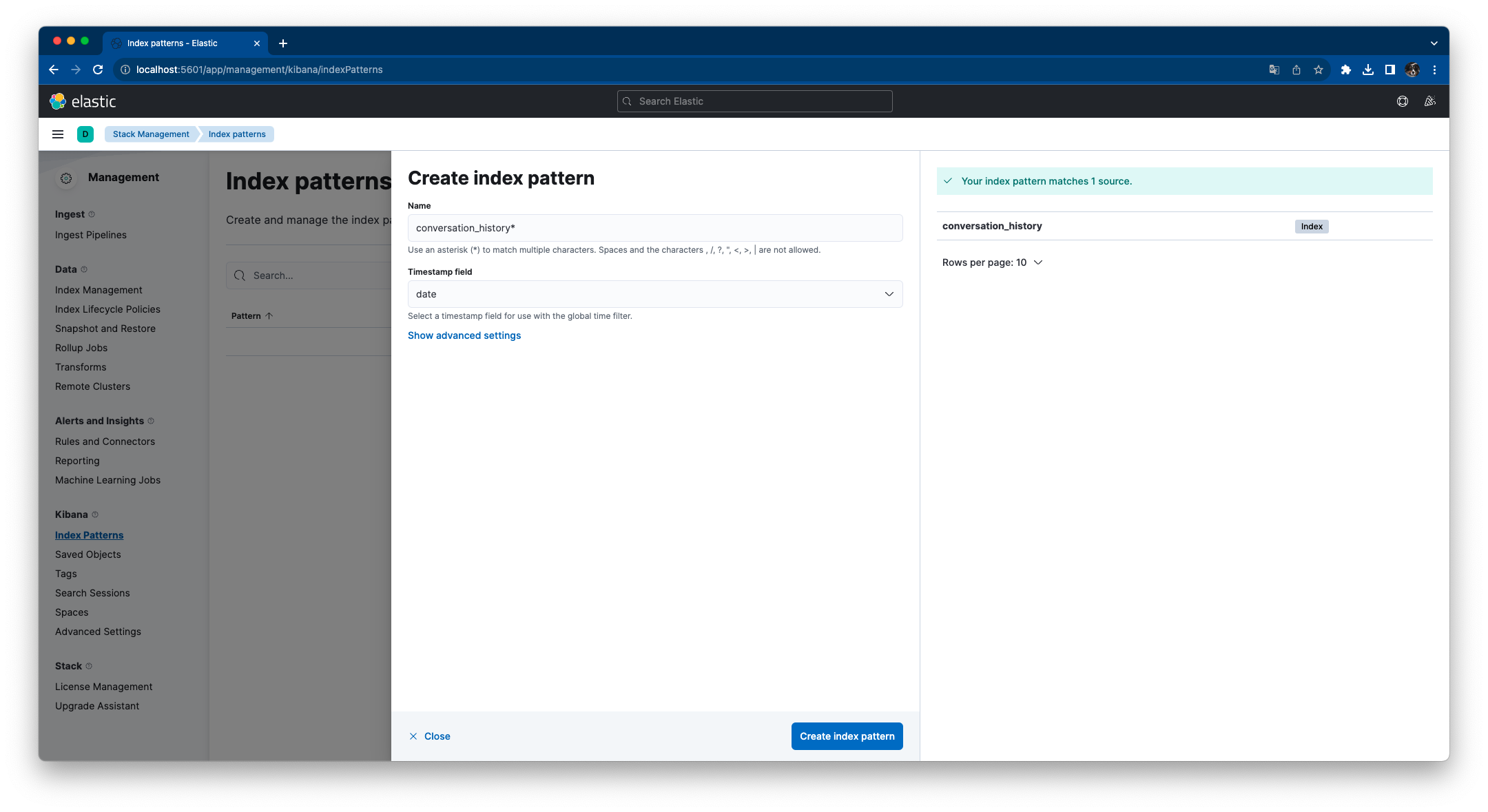
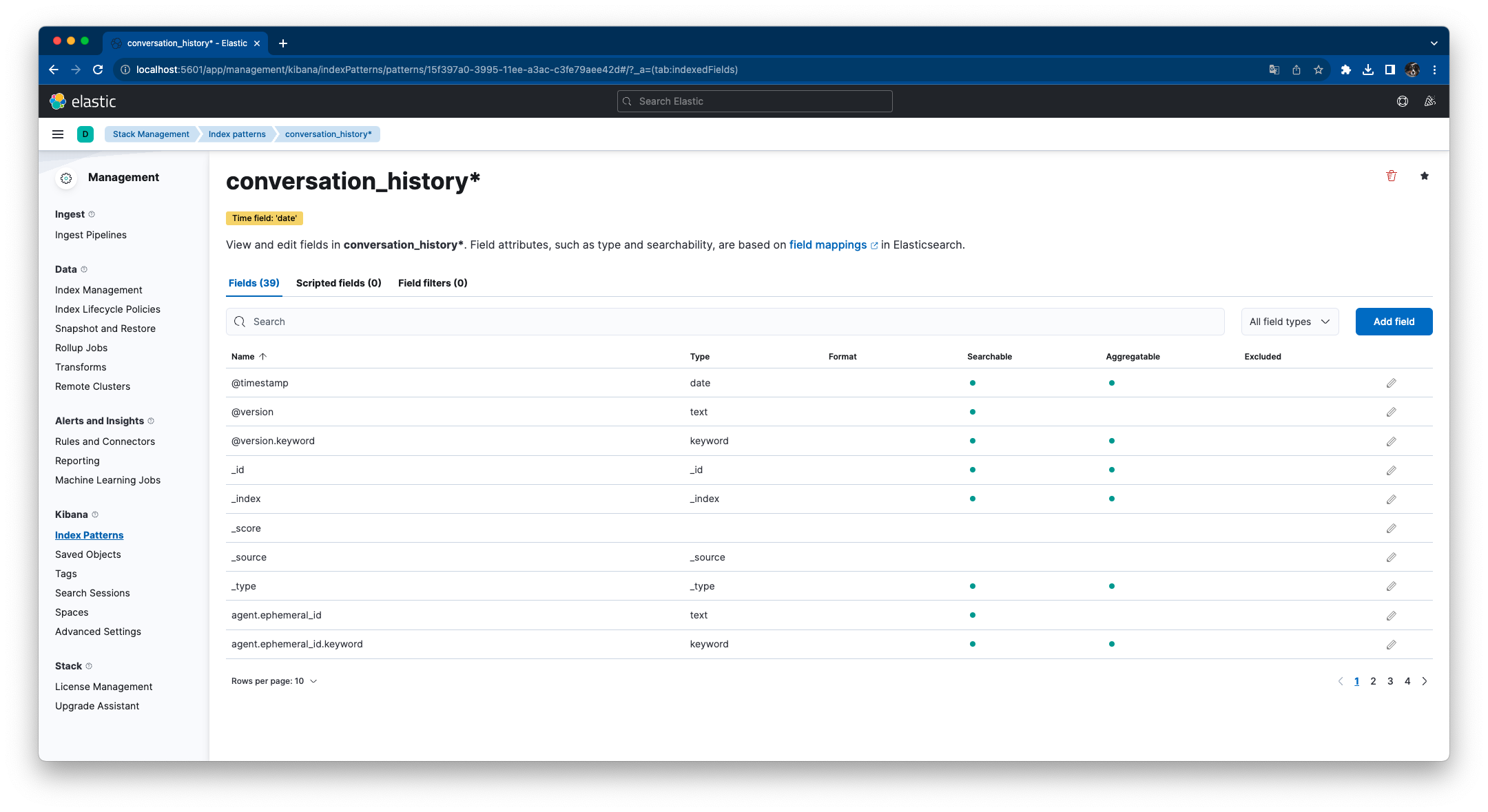
Kibanaインデックスパターンが作成されます。
Kibanaデータ可視化
全文検索
Analytics Discoverをクリックします。
投入したデータが表示されます。
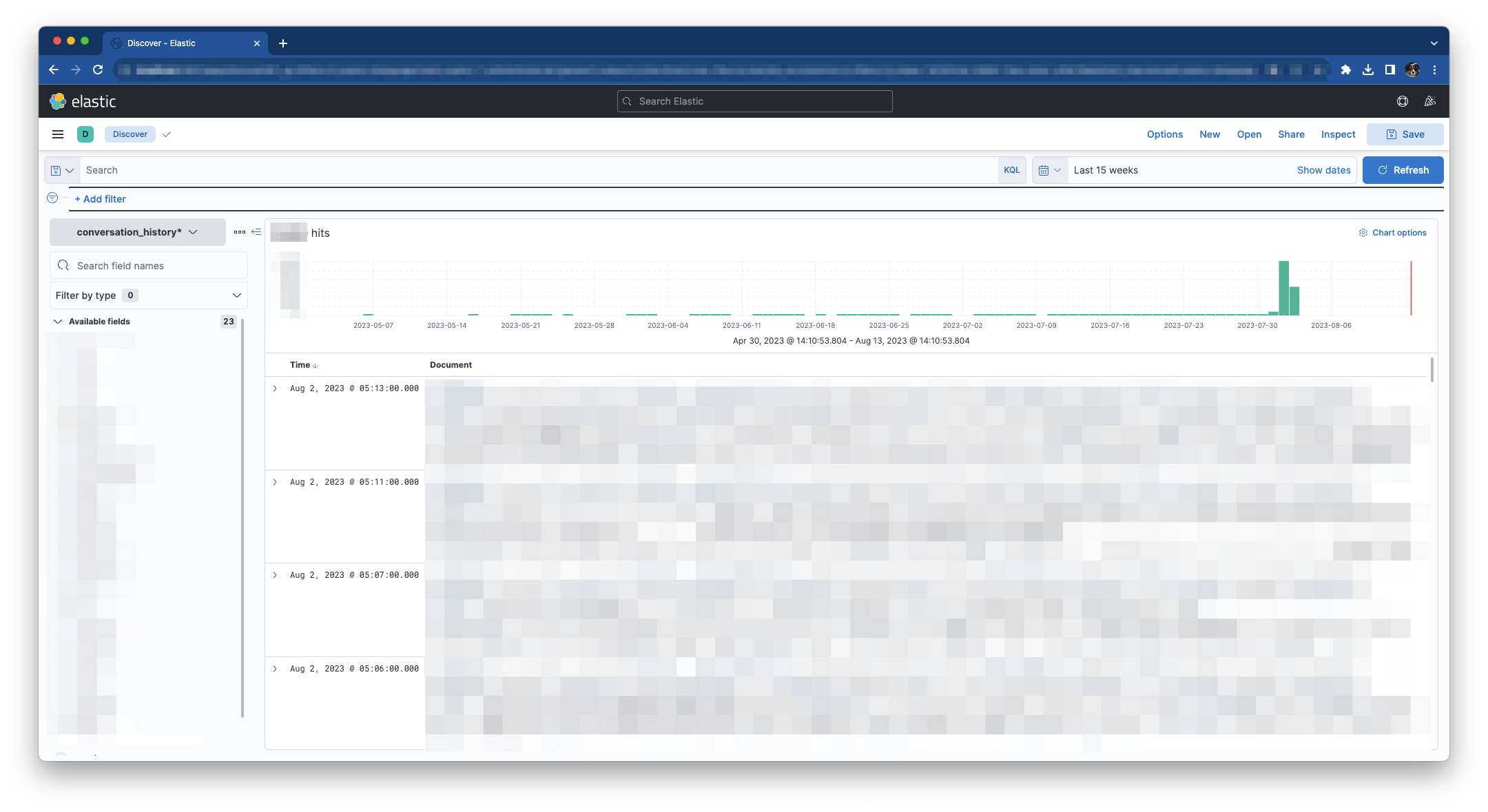
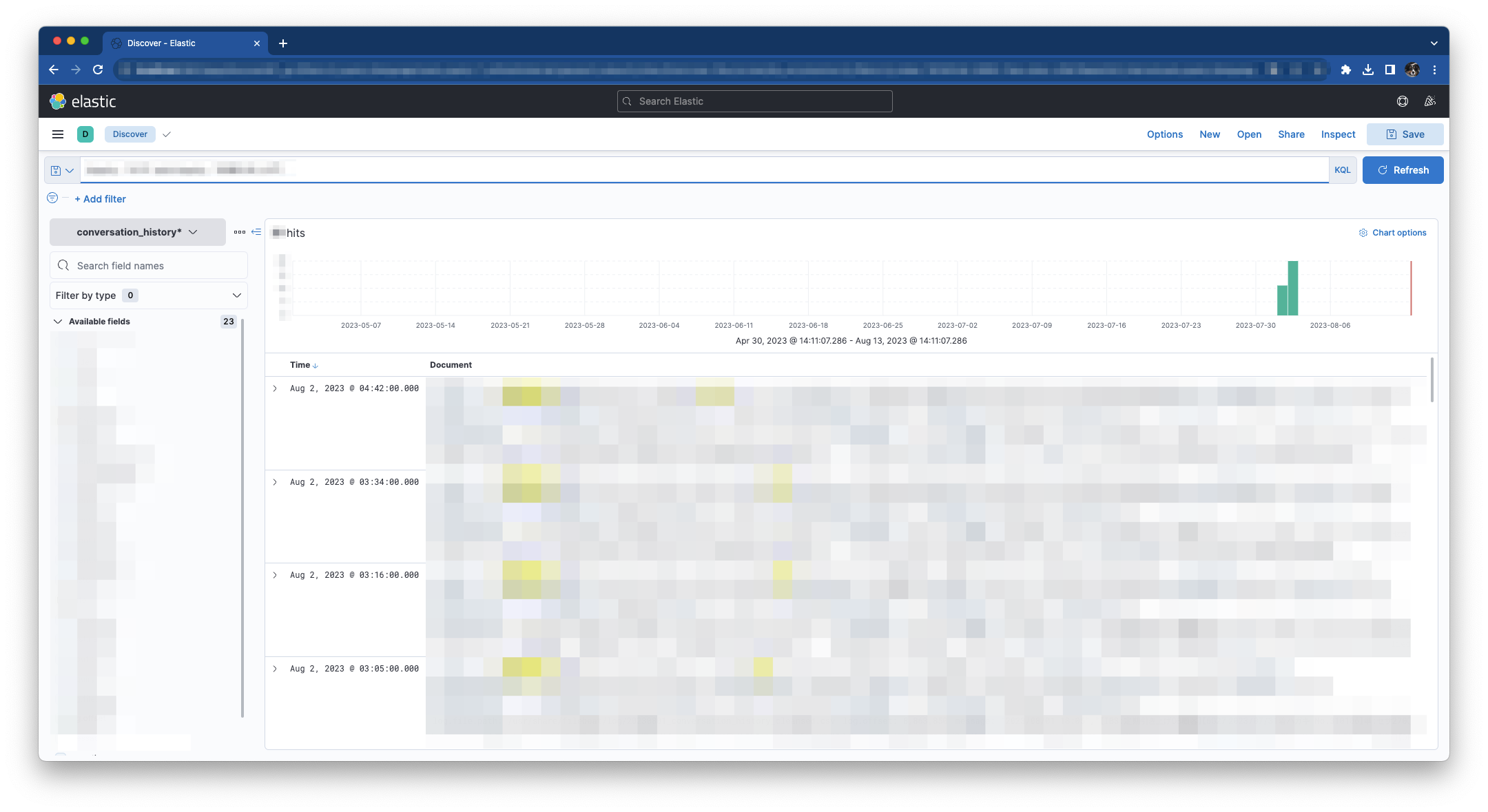
例えばテキストボックスに「conversation : “セサ”」と入力しEnterを押下すると「セサ」が含まれるレコードがヒットします。
(画像にモザイク処理をかけていてわかりにくいですが、検索にヒットしたキーワードに黄色でマーカーが引かれます。弊社ではセサミンをセサと略して表現することが多いです。)
タグクラウド
Kibanaではタグクラウドを作成することが出来るので試作しました。
Analytics Visualize Library > [Create new visualization] をクリックします。
Aggregation basedをクリックします。
Tag cloudをクリックします。
インデックスパターンを選択します。
Buckets > Add > Add bucket / Tagsをクリックします。
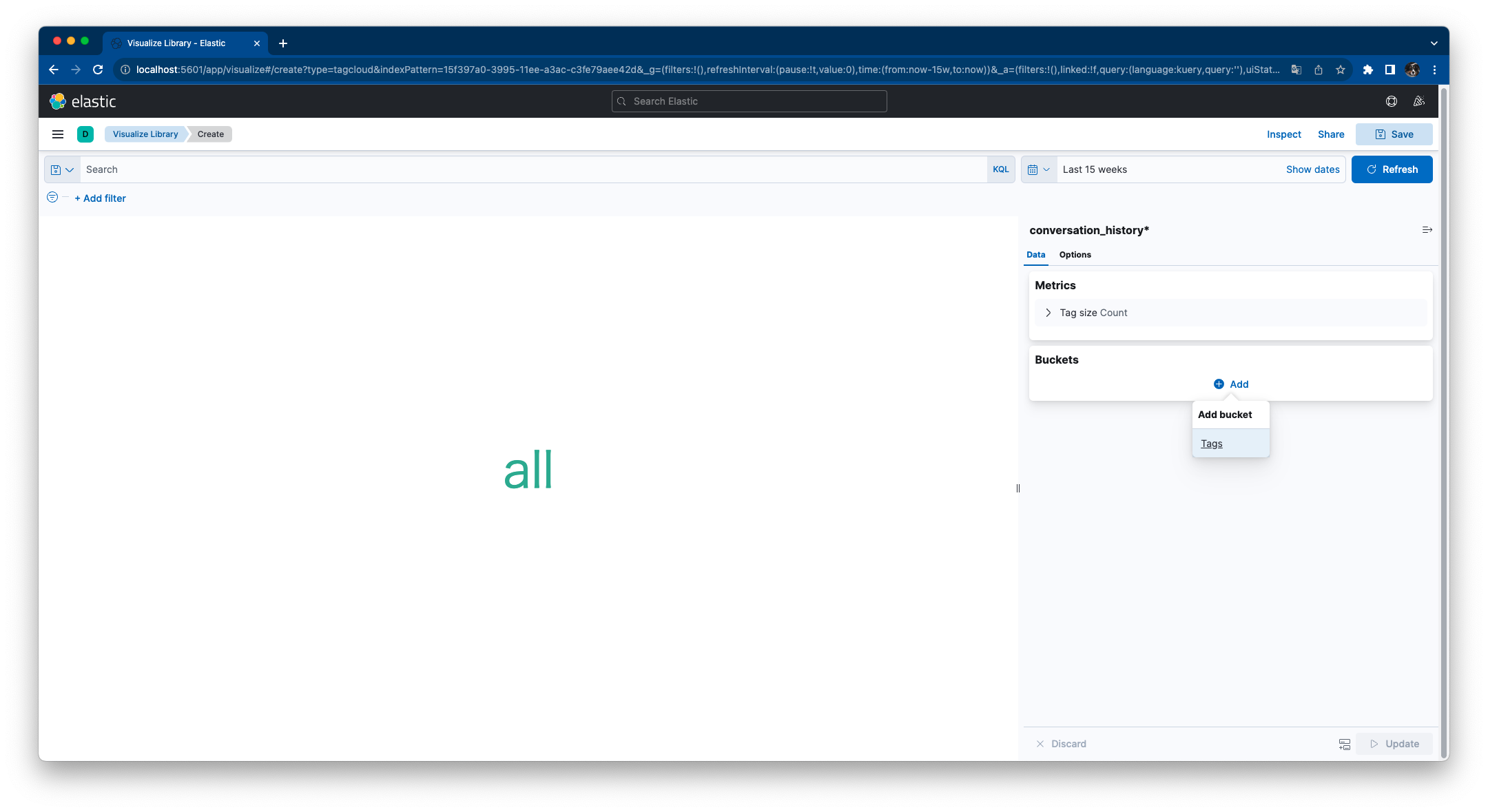
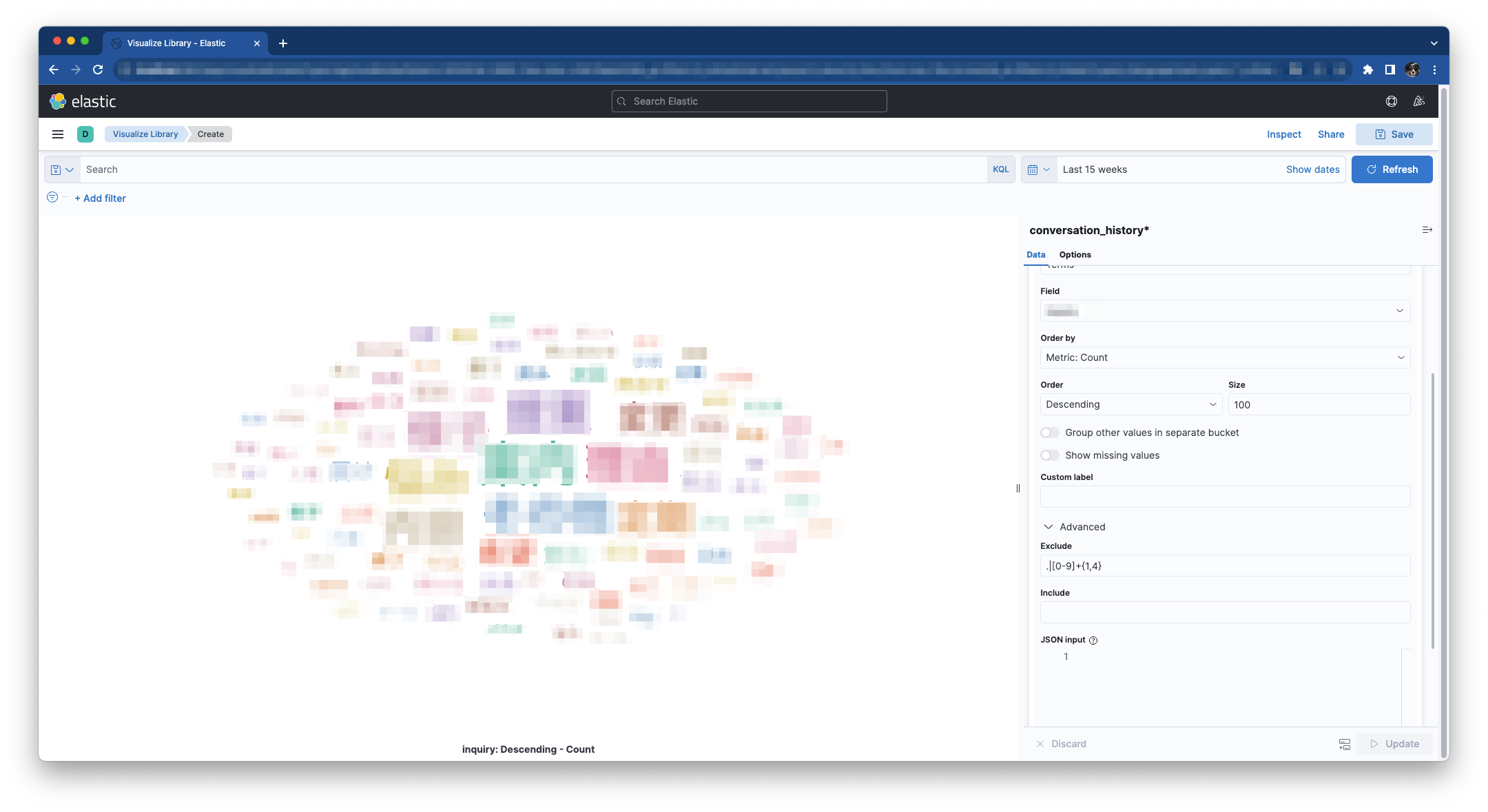
下記設定し [Update] をクリックするとタグクラウドが表示されます。
| key | value | |
|---|---|---|
| Aggregation | Terms | |
| Fields | conversation | |
| Size | 100 | |
| Exclude | .\ | [0-9]{1,4} |
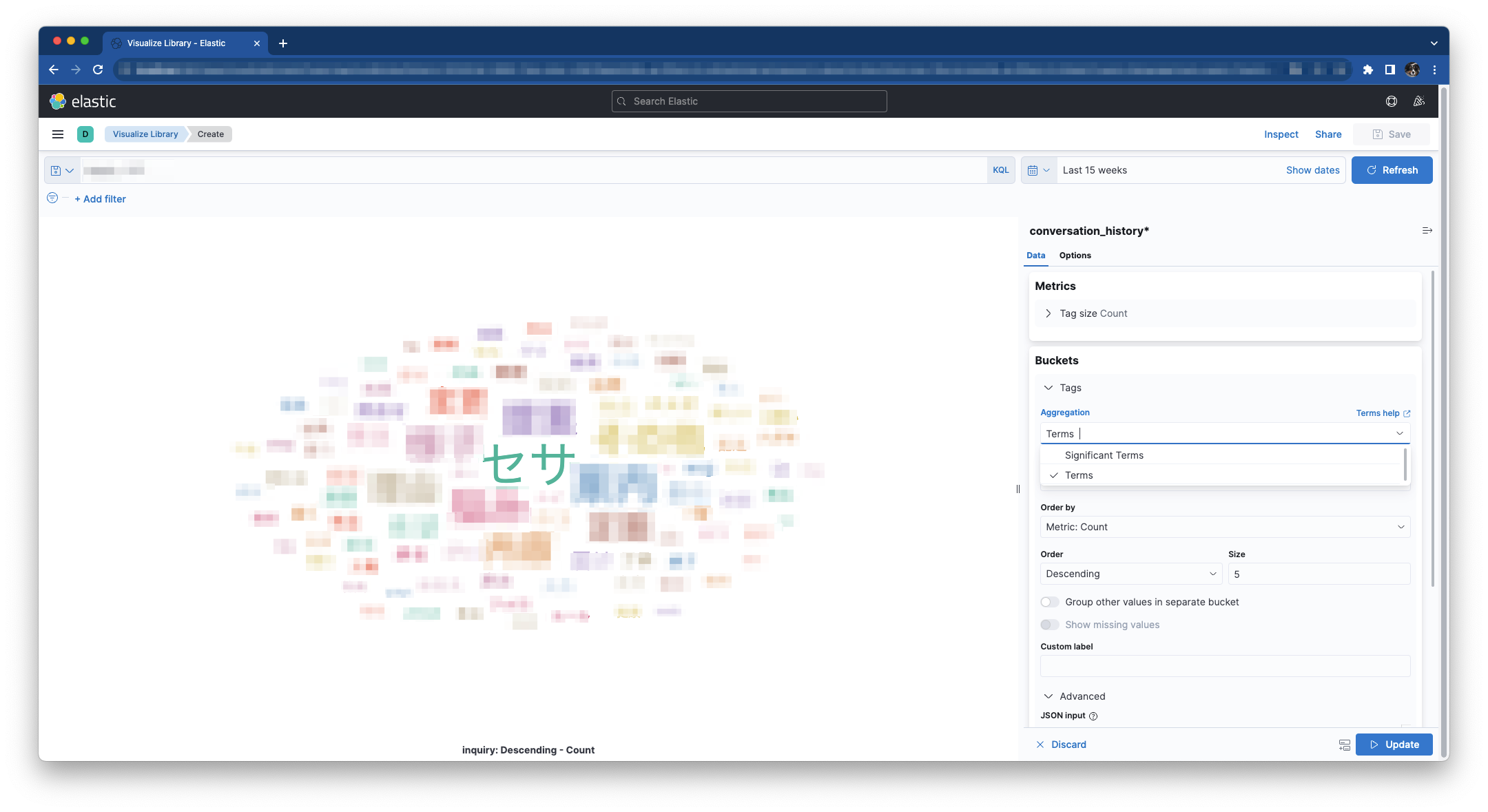
テキストボックスに「conversation : セサ」と入力しEnterを押下するとセサに関するタグクラウドが描画されます。
まとめ
この記事ではテキストデータをElasticsearchに投入して全文検索出来るようにする方法を紹介しました。
今回はCSVファイルを取り込みましたが、それ以外のフォーマットでもデータを連携することが出来るので是非お試しください。
(こちら内部で共有したところ柔軟に検索出来るようになって良さそうと好評でした。デモを作成してみて良かったです。)