サントリーウエルネスDX推進部の武田です。
フルスタックエンジニアとしてコンタクトセンターで使うシステムが抱える課題に日々取り組んでいます。
2023年10月に対話要約プロジェクトを立ち上げ、GPTで業務適用レベルの要約が得られること、GPTで業務時間が削減されることを短期間で実証しました。

ここで、プロジェクトを成功に導くために色々試行錯誤して孝動したことについて振り返ります。
対話要約プロジェクトについてはこちらの記事にて活動内容を詳しく記載していますので、ぜひご覧ください。
振り返り
様々な切り口から振り返ります。
プロジェクト構想
プロジェクト発足前の構想段階での考動について振り返ります。
人で実施する部分とシステムで実施する部分を見極める
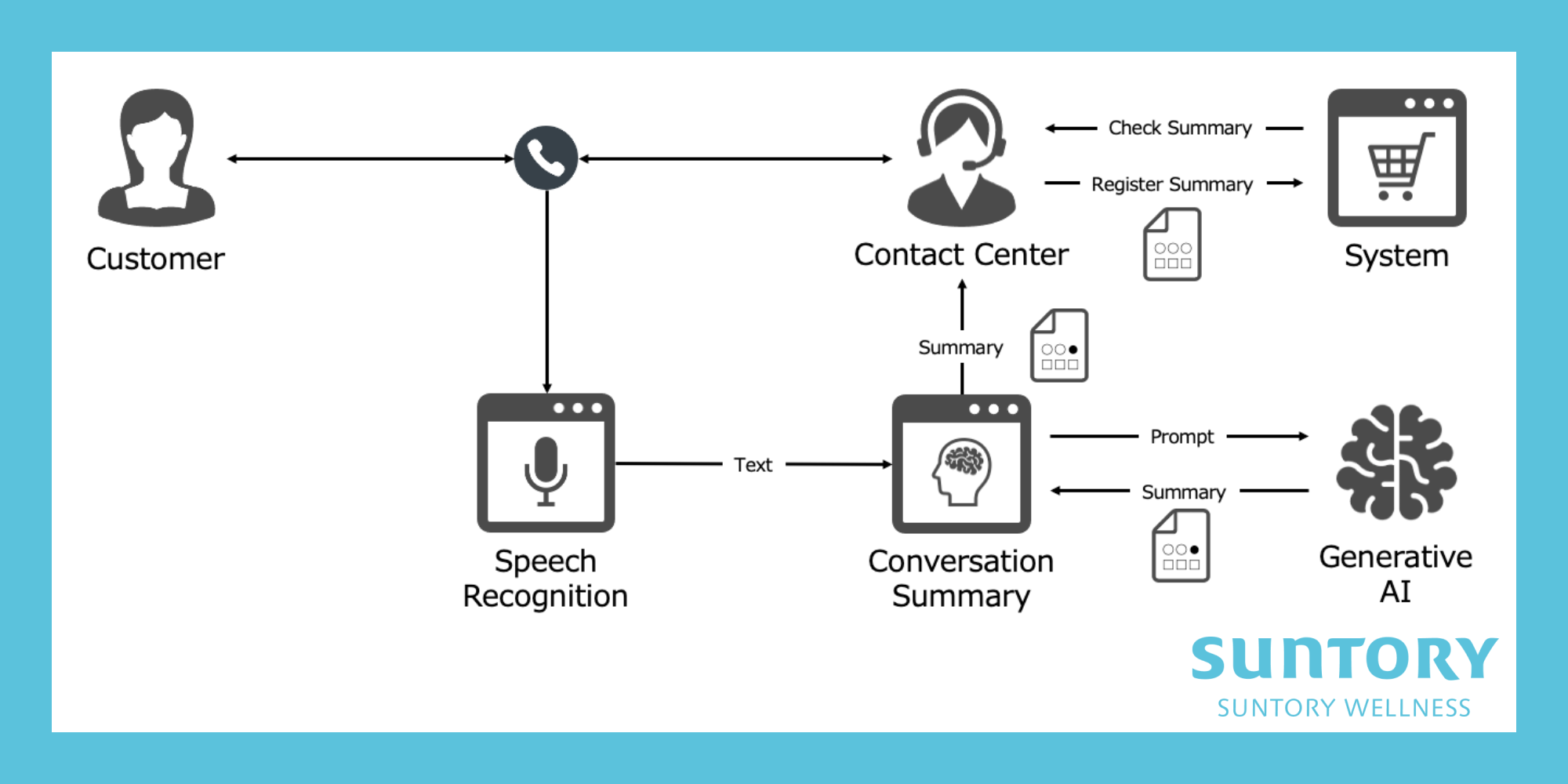
対話要約では、お問い合わせ内容(以降、リーズン)を判断し、リーズンに応じた要約を作成する必要があります。
仮にリーズン判断、要約の精度がそれぞれ80%としたとき、全体を通して見ると精度は64%になってしまいます。
現時点ではリーズン判断、要約ともに人で実施しており、リーズン判断については人で実施してもそこまで負担にならないかつ、精度もAIより高いため、リーズン判断を人で実施し、要約をGPTで実施する方針としました。
そうすることで、プロンプトとしては要約に注力でき、短期間で現場適用レベルのプロンプトの作成に至りました。
何でも生成AIで実現しようとせず、対象業務を俯瞰して成果を最大化するために、人で実施する部分とシステムで実施する部分を見極めるという視点も重要だと考えています。

タスクを分解し簡単にする
商品の注文をはじめ、配送日の変更、キャンペーンなどリーズンは様々です。
また、リーズンごとに要約に含めたい内容も異なります。
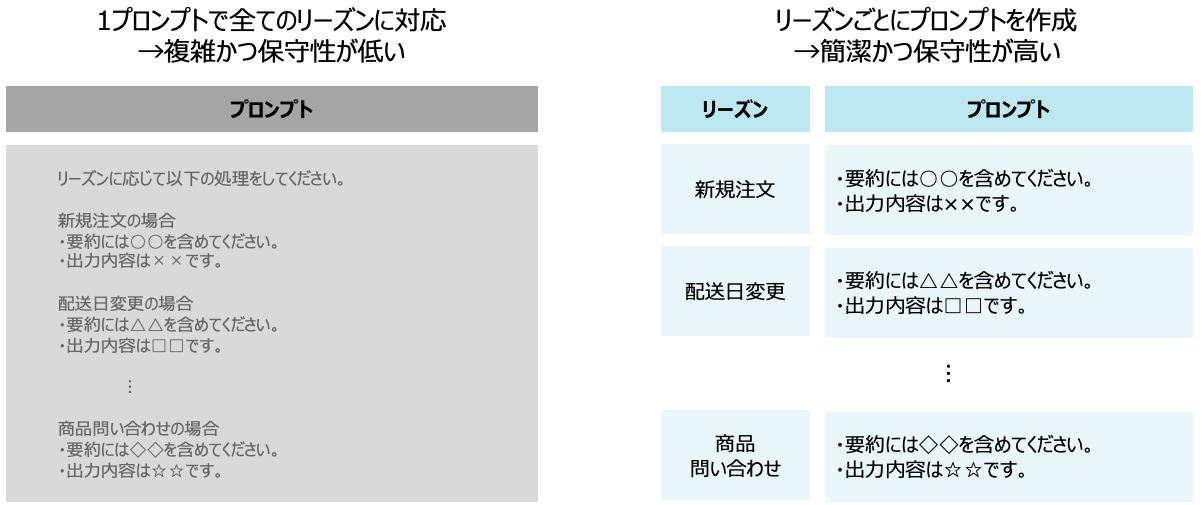
リーズンごとに要件が異なる中で、全てのリーズンの要約を1個のプロンプトで実現するのは非常に難しいのではないかと考えました。
そこで、全てのリーズンを要約できるプロンプトを作るのではなく、リーズンごとにプロンプトを用意する方針にしました。
結果、リーズンごとに必要な情報、不要な情報を定義し、そのリーズンに特化したプロンプトを作り上げ、精度の向上に至りました。
ここで言いたいことは、複雑で実現困難に見えるタスクも、分解して小さいタスクにすることで、簡単にできる可能性があるということです。
プロジェクトの特性に応じた進め方を適用する
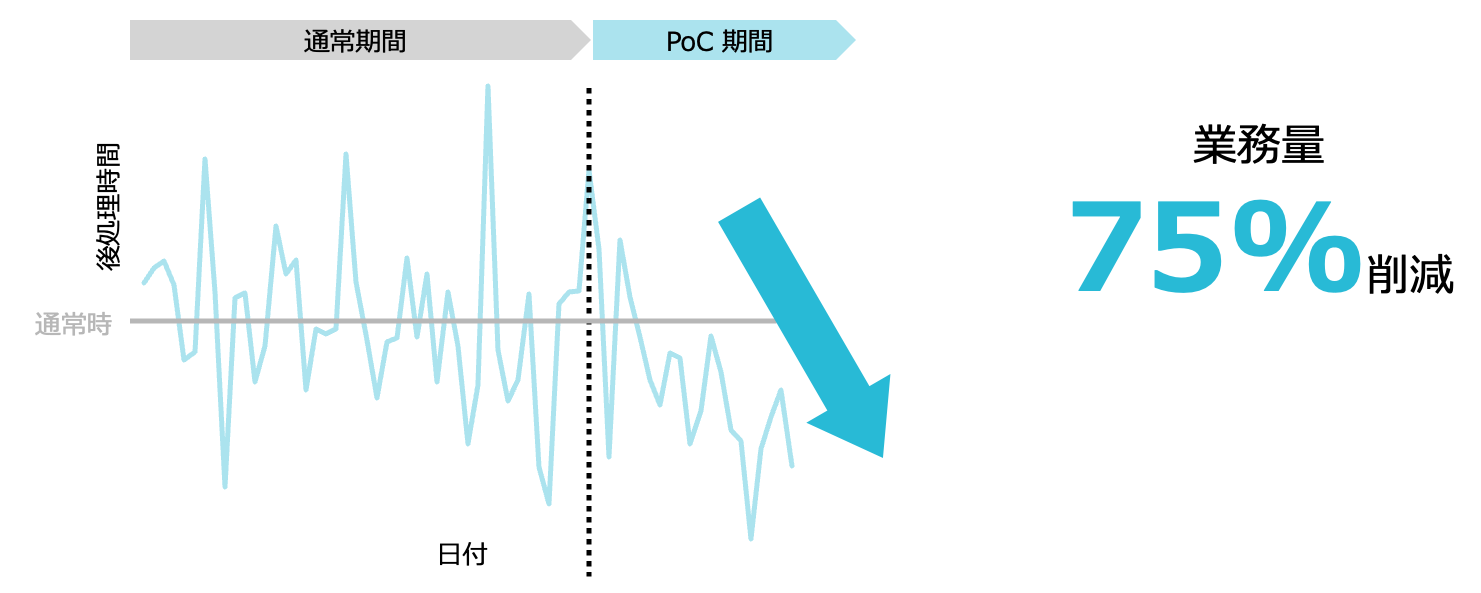
対話要約では、GPTが作成する要約が現場適用できるレベルに達するか、対話要約により現場の負荷が本当に削減されるのか、PoCを実施する必要がありました。
非常に不確実性の高いプロジェクトだったため、迅速かつ柔軟にプロジェクトを進めるためのフレームワークである、スクラム開発を採用しました。
私以外スクラム開発未経験ということもあり、完全なスクラム開発にはせず、プロジェクトでやるべきことを可視化→スプリント(タスクに取り組む一定期間)で取り組むことを決めて実施→定期的に状況を確認→やるべきことをアップデートといったように柔軟に進めました。
プロジェクト推進
プロジェクトを推進する際の考動について振り返ります。
プロジェクトの基盤を整備する
プロジェクトを立ち上げる際に環境とルールを整備しました。
- Confluenceにプロジェクト用のスペースを作成し、議事録、調査内容、成果物などのドキュメントを格納する
- Jiraにプロジェクトを作成し、タスク、作業状況を可視化する
- Slackにプロジェクト用のチャンネルを作成し、コミュニケーションを取る
ドキュメントの作成はConfluence、タスク管理はJira、日々のやり取りはSlackといったように、どこで何をするかを明確にすることで、プロジェクトを円滑に進めることができました。
各自がタスクに集中できるようにする
各自がタスクに集中できるように私がスクラムマスターとしてプロジェクトを推進しました。
- PoCを進めるために必要なタスクを全て可視化する
- 優先度を考慮して、スプリントごとに取り組むタスクを決め、担当者をアサインする
- 定例会でタスクの状況を確認する
プロジェクトの進行やタスクの差配を私が全て引き受けることで、コンタクトセンターがGPT出力評価に、SST(サントリーグループのITサービス会社であるサントリーシステムテクノロジー)がプロンプトチューニングに集中できたからこそ、短期間で成果が出せたと考えています。
足りないピースを補完する
GPT出力要約が現場適用できるレベルに達するかPoCを始めるためには、下記のように色々タスクがありました。
- プロジェクト立ち上げ
- 対象リーズン検討
- 評価データ準備
- 評価条件検討
- PoC終了条件検討
- …
これらのタスクを全て私が引き取り、PoCの準備をしました。
プロジェクトを軌道に乗せるために足りないピースを埋める動きをしたことで、円滑にプロジェクトを進められたと考えています。
プロンプトチューニング
現場適用レベルの要約を生成するプロンプトを作成する際の考動について振り返ります。
評価対象を検討する
「タスクを分解し簡単にする」の項でも記載しましたが、商品の注文をはじめ、配送日の変更、キャンペーンなどリーズンは様々です。
リーズンが多岐に渡るため、短期間で全てのリーズンに対してPoCを実施することは現実的でありませんでした。
そこで、過去のお問い合わせのリーズンごとの件数を集計し、件数上位に絞り主要なリーズンに対してPoCを実施することにしました。
評価条件を定義する
プロンプトチューニングによって精度が向上したかを評価するために、評価条件を定義しました。
要約において定量評価の指標としてROUGE-Nが使われます。
ROUGE-Nは生成要約と正解要約がN-Gram単位でどれだけ一致しているかを表します。
しかし、N-Gramはn個の文字のまとまりを示すため、ROUGE-Nでは生成要約が正解要約とどれだけ文字単位で一致しているかしか計れません。
これは同じニュアンスの言い換え表現を計測できないことを意味しています。
そこで、人手で要約の精度を5段階で評価したり、情報が抜けていないか不必要な情報が含まれてないかなどの観点を洗い出して評価したりするなどの定性評価をし、5段階評価の平均や各観点の件数で精度を評価することにしました。
評価条件を定義することで、なんとなくで評価するのではなく、数値として精度が向上したのかを評価できました。
生成AIが銀の弾丸ではないことを理解する
これを考動の例に挙げるのは微妙かもしれませんが、生成AIを扱ううえで大事な考えだと思うので記載します。
GPTに代表される文章生成AIは簡単に言うと、「与えられた文章に続く最も確率が高い文章を生成する技術」です。
例えばGPT-4oに「1番高い山は何ですか?」と聞くと「世界で最も高い山は、エベレスト山です。標高は約8,848メートル(29,029フィート)で、ネパールと中国の国境に位置しています。」という回答が得られます。
ところが、富士山という回答を得たかったとすると、「日本で1番高い山は何ですか?」と聞く必要があります。(回答は「日本で最も高い山は、富士山です。標高は3,776メートルで、静岡県と山梨県にまたがっています。」となります。)
さらに、回答に標高やどこにあるかといった情報を求めていないとすると「日本で1番高い山は何ですか?山の名前だけ教えてください。固有名詞のみを出力してください。」と聞く必要があります。(回答は「富士山」となります。)
この例で伝えたかったことは、生成AIは使う側の意図を組んでよしなに回答してはくれず、欲しい答えを得るためには、何(例では日本で1番高い山の名前)をどのような形(例では山の名前のみ)で欲しいのかを言語化して伝える必要があるということです。
出力として何を得たいのか徹底的に言語化する
文章生成AIは「与えられた文章に続く最も確率が高い文章を生成する技術」で、欲しい回答を得るためには何をどのような形で欲しいのかを言語化して伝える必要があります。
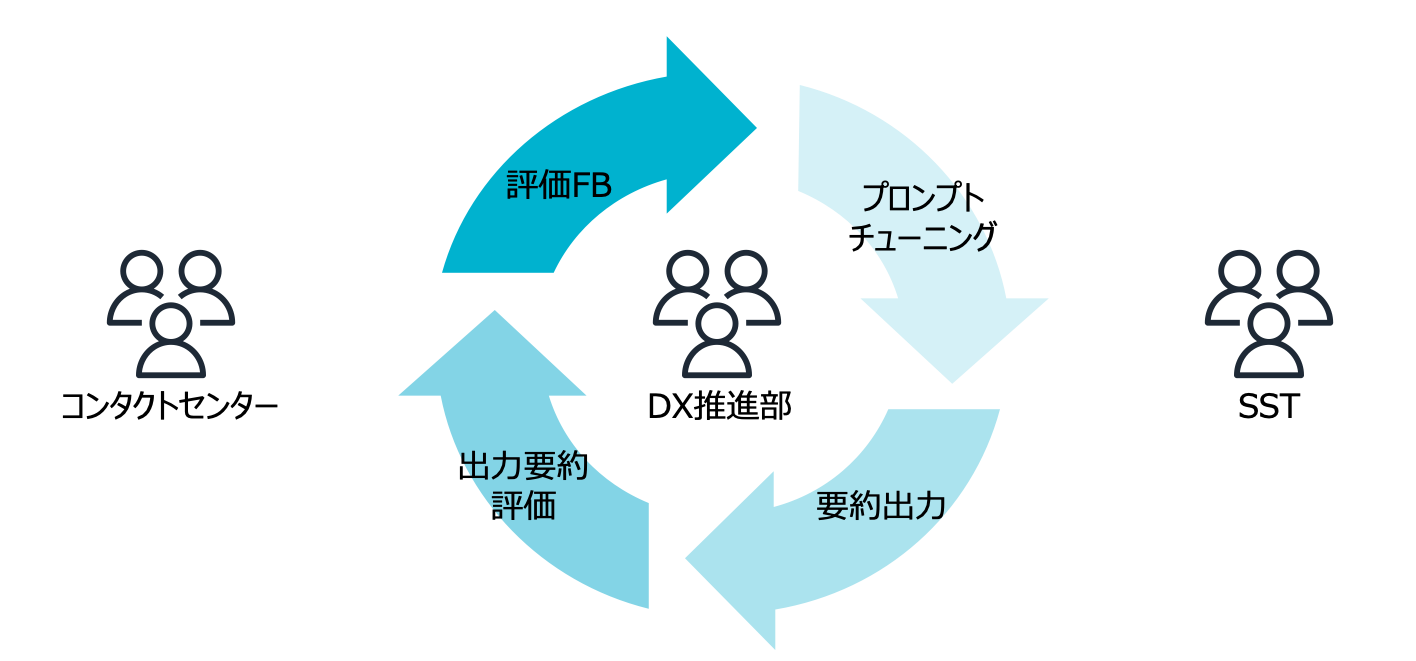
なので、コンタクトセンター側でGPTの出力要約を評価する際に要約にどういった情報が必要で、またどういった情報は不要なのか言語化をお願いしました。
現場でGPT出力要約を評価→現場から開発者に評価をFB→プロンプトチューニング→GPTで要約を出力→出力要約を評価→…といったようにプロンプトチューニングのサイクルを高速で回し、要約として必要な情報を徹底的に言語化しました。
結果、短期間で現場適用レベルのプロンプトの作成に至りました。
システム開発
対話要約機能を開発する際の考動について振り返ります。
サンプルコードを共有する
GPTのREST APIをシステムに組み込むのがはじめてということもあり、GPTのREST APIを実行するサンプルを実装し、開発チームに連携しました。
動くサンプルを共有することで、GPTのREST APIに対する理解も深まり、開発もスムーズに進みました。
GPTの処理時間を考慮したアーキを検討する
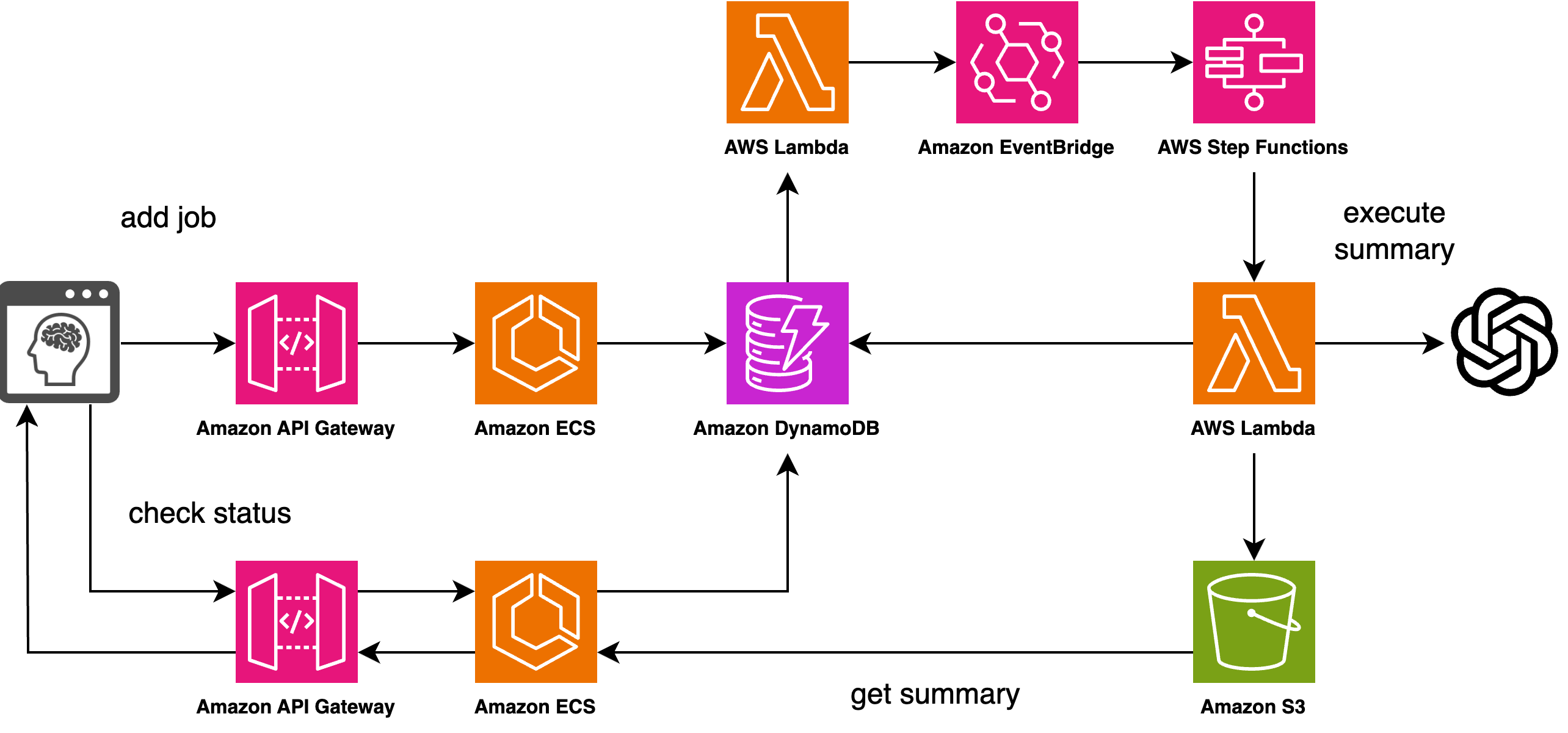
当初、既存APIに対話要約用のエンドポイントを新規で作成することを想定していました。
しかし、プロンプトチューニングを実施する際にGPTの処理時間を計測したところ、最大で1分近くかかる場合がありました。
既存APIではタイムアウト値に上限があり、GPTの処理が完了する前にAPI側でタイムアウトになってしまう恐れがありました。
そこで、以下のように非同期処理で対応することにしました。
- 要約を開始したら、GPTにプロンプトを送信する
- 画面からはGPTの処理状況を定期的に確認する
- GPTの処理完了を検知したらGPTの出力を取得し画面に表示する
システムアーキを検討する際に、前もって使う技術の制約を考慮に入れることで最適なアーキを選択できます。
実証実験
対話要約機能によって業務時間が削減されるか実証実験する際の考動について振り返ります。
導入効果の指標を定義する
要約機能の導入効果を数値で確認するために以下の指標を定義しました。
| 指標 | 概要 |
|---|---|
| 要約活用率 | 要約機能がどれだけ活用されたか |
| 修正率 | GPT出力要約がどれだけ手直しされたか |
| GPT処理時間 | GPTの処理時間 |
| 後処理時間 | 通話終了後の作業時間 |
業務時間がどれくらい削減されたかが最も見たい数値ではありましたが、その他にも実際にGPTの出力がどれくらいそのまま使えているかやGPTでどれくらい処理に時間がかかっているか、といった観点も指標に組み込みました。
導入効果を可視化する
前項に挙げた指標を日次でローデータから算出し、要約機能の導入効果を可視化しました。
| 指標 | 算出方法 |
|---|---|
| 要約活用率 | 要約実行回数/システムに登録された要約件数で算出 |
| 修正率 | GPT出力要約とシステムに登録された要約がどれだけ一致しているかをROUGEで算出 |
| GPT処理時間 | 要約機能の実行ログから算出 |
| 後処理時間 | CTIから算出 |
指標の可視化の他に、GPTの出力が社内システムに登録される際に現場で具体的にどの箇所を手直ししているかも可視化しました。
これについては、PythonでGPTの出力要約と社内システムに登録された要約の差分をhtmlで出力するスクリプトを書いて対応しました。
おわりに
プロジェクトを成功に導くために色々試行錯誤して考動したことについて整理しました。
生成AI活用で最も重要なことは解決したい問題と生成AIで何のタスクを代替するかを明確にすることです。
今回のケースは「対話要約の業務負荷が高い」という問題に対して、人でリーズンを判断し、生成AIで「リーズンごとに所定のフォーマットで対話を要約する」となります。
その他にも、不確実性が高いことからスクラム開発を採用する、ユーザーやデベロッパーを巻き込んでプロンプトチューニングのサイクルを回すなど様々なエッセンスを紹介しました。
この記事が生成AI活用プロジェクトの推進の一助になれば幸いです。